728x90
반응형
💡
loss function : 모델의 inference 결과(예측값)와 실제 값(y) 사이의 틀린 정도를 계산하는 함수
- (predictied value)와 (target value) 사이의 차이를 계산해주는 함수.
- 덜 틀릴 수록(= 차이가 적을 수록) 학습을 잘한 것입니다.
- 그럼 Loss function의 결과에 영향을 주는 변수는 무엇일까?
→ parameter! (eights)
- Loss function의 계산 결과가 가장 작아질 수 있는 parameter를 찾는 것이 학습의 목표가 됩니다.
Loss Function Optimization
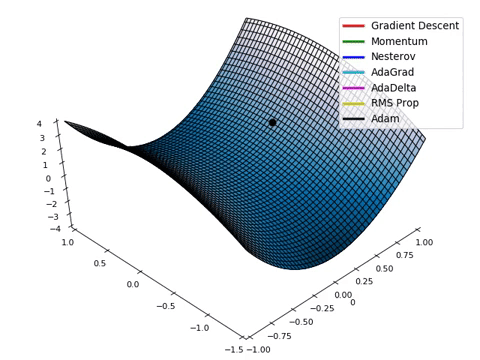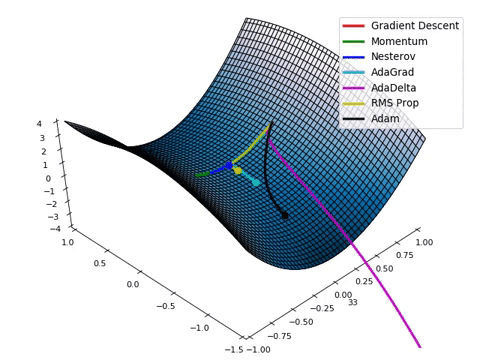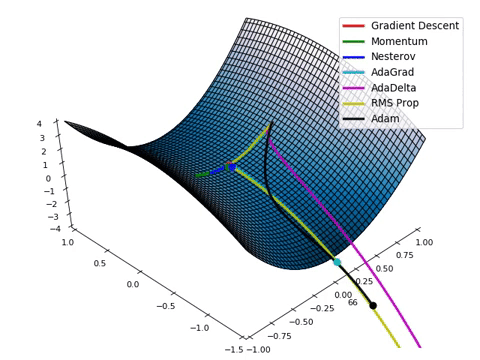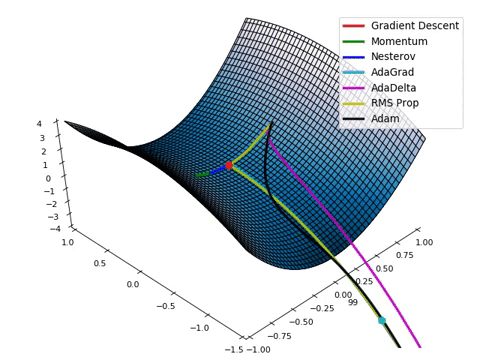
- Loss function이 최적의 값을 가질 수 있는 파라미터를 찾기 위해서는 파라미터를 적절하게 업데이트 해주어야 합니다.
- 성능이 향상되는 방향으로 파라미터를 업데이트 해주는 것이 중요합니다!
- Loss space에서 최적의 파라미터 조합을 찾는 문제는 수학적으로 매우 어렵습니다. (고차원에서의 최적화 문제는 해답을 찾기가 어려움)
- 현실적으로 최적의 파라미터 조합을 찾을 수 있는 “
Gradient Descent Algorithm” 이 제일 많이 사용됩니다.
Source : https://blog.clairvoyantsoft.com/the-ascent-of-gradient-descent-23356390836f
- Gradient Descent algorithm은 임의의 포인트에 떨어졌을 때, 현재 서 있는 위치에서 가장 가파른 방향으로 한 발자국씩 내려가는 방법으로 최선을 다해 밑바닥으로 내려갈 수 있는 방법입니다.
- practical하게 굉장히 좋은 파라미터 조합을 잘 찾아주며, 대부분의 머신러닝 모델에 적용되어 있는 최적화 방식입니다.
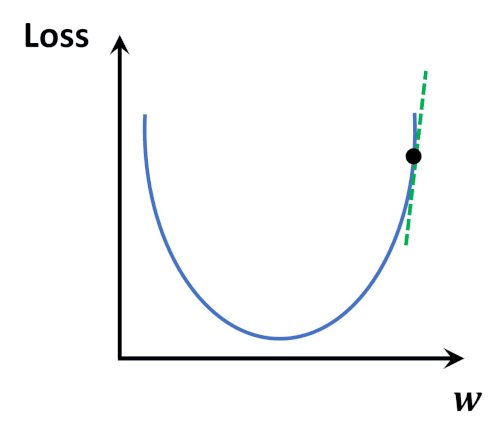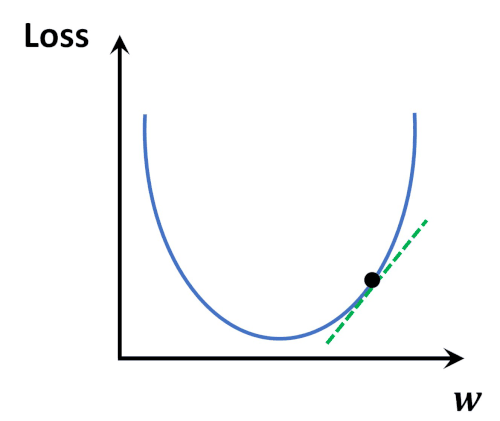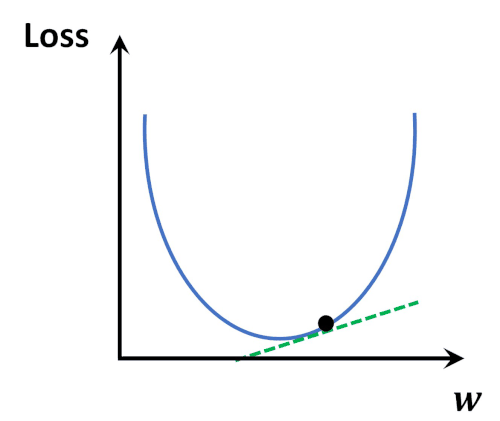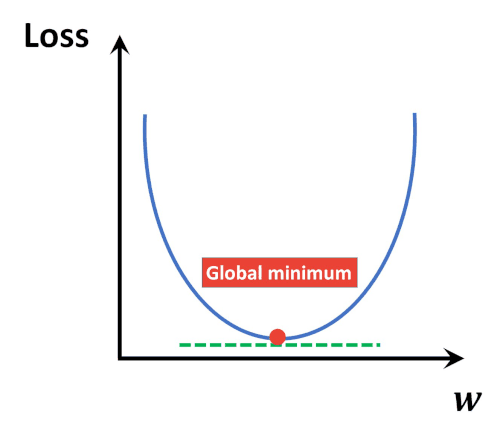
- Gradient Descent algorithm은 파라미터가 점차 Loss function에서 최소값을 가질 수 있게 파라미터를 업데이트 해줍니다.
- 단, 무조건 global minimum(최소값)을 찾는 것은 아닙니다. local minimum(극소 값)을 찾을 수도 있습니다. (하지만, 극소값은 무조건 찾습니다.)
Hands-on
- 머신러닝에서 사용되는 대표적인 Loss Function을 3가지만 조사해보세요. (분류, 회귀, 클러스터링에서 하나씩 찾아보면 제일 좋습니다!)
- Loss function optimization에서 수학적으로 최소값을 찾는 analytic solution 대신, Gradient Descent를 주로 사용하는 이유는 무엇일지 생각해보세요.
728x90
반응형
'AI Study > DeepLearning' 카테고리의 다른 글
| Chapter.02 Machine Learning Workflow-01. 머신러닝 프로젝트 수행방법 (0) | 2023.04.14 |
|---|---|
| Chapter.01 머신러닝 기초 개념-07. evaluation metric (0) | 2023.04.14 |
| Chapter.01 머신러닝 기초 개념-05. feature engineering (0) | 2023.04.11 |
| Chapter.01 머신러닝 기초 개념-06. loss function (0) | 2023.04.11 |
| Chapter.01 머신러닝 기초 개념-04. inference (0) | 2023.04.11 |